Data science is a vast and exciting field, brimming with the potential to unlock valuable insights. But like any seafaring voyage, navigating its currents can be challenging. Data wrangling, complex models, and siloed information – these are just a few of the obstacles that data scientists encounter.
Fortunately, there's a trusty first mate to help us on this journey: Microsoft Fabric. Fabric isn't a single tool, but rather a comprehensive set of services designed to streamline the data science workflow. Let's set sail with an example to see how Fabric equips us for smoother sailing.
The mission of a data scientist is to develop a model to predict when a customer will stop using a service (customer churn). Here's how you can use Fabric can be your guide
Predicting Customer Churn
Let's dive deeper and explore the steps involved in building a customer churn prediction model using Microsoft Fabric. You can get started by signing into http://fabric.microsoft.com using your cruise tickets for your data science journey.
Step 1: Data Discovery & Acquisition
- Mapping the Treasure Trove: Utilise Microsoft Purview, the unified data governance service within Azure Portal. Purview acts as your treasure map, helping you discover relevant datasets related to customer demographics, purchase history, and marketing interactions. You can add your own datasets and register them.
- Charting the Course: Once you've identified the datasets, leverage Azure Data Factory to orchestrate data extraction, transformation, and loading (ETL) processes. Data Factory acts as your captain, guiding the data from its source to your designated destination (e.g., One Lake). You can also avoid the above two steps and directly chart your course with the existing open datasets and notebooks available in the sea of Microsoft Fabric which is what we will be doing here.
- Unveiling the Data in OneLake: As you navigate the vast seas of ocean (data), OneLake, a central data repository within Fabric, serves as your treasure trove. Utilise the Lakehouse item, your personal submarine, to explore and interact with the relevant datasets that are crucial for your customer churn prediction mission. After signing in, enter into the Data Science cabin as shown in the below image

Click on Use a Sample as shown below


- Attaching the Lakehouse to Your Notebook: Effortlessly connect the Lakehouse containing your relevant datasets to your analysis Notebook. This allows you to browse and interact with the data directly within your notebook environment.
To do this click on lakehouse link section of the left navigation pane of the Notebook as shown below and create a New Lakehouse

- Prepare for sailing: Bring the right luggage for sailing by installing the right libraries. To do this run the below code using the pip install command from the notebook as shown below

Prepare your travel documents by exploring the dataset that you are going to use which is the bank dataset that contains churn status of 10,000 customers with 14 attributes. Run the below configuration to prepare as shown below

Prepare to combat seasickness by downloading the dataset and uploading it to the lakehouse by running the cell as shown below

- Seamless Data Reads with Pandas: OneLake and Fabric Notebooks make data exploration a breeze. You can directly read data from your chosen Lakehouse into a Pandas dataframe, a powerful data structure for analysis in Python. This simplifies data access and streamlines the initial stages of your data exploration.
Prepare your groceries by running the next two cells and create a pandas dataframe as shown below

Plan your sailing itinerary by running the next two cells as shown below
- Setting Sail with DataWrangler: DataWrangler, your powerful workhorse, welcomes the acquired data frame. Here, you'll have an immersive experience to clean and prepare the data for analysis. This might involve handling missing values, encoding categorical variables, and feature engineering (creating new features based on existing ones).
Have the main mooring lines looped through to manouver by running the datawrangler from the Data tab of the notebook as shown below

Choose the dataframe that you created in the next screen as shown below

Now the Data Wrangler is launched, expand the find and replace and click on the drop duplicate rows as shown below

This will create the code for dropping the duplicate rows from the dataframe if there are any as shown below

- Exploring the Currents: Perform Exploratory Data Analysis (EDA) to understand the data's characteristics. Identify patterns and relationships between features that might influence customer churn.
Start moving only after checking that no other boat is already manoeuvring in the same channel arm by running the next three cells as shown below


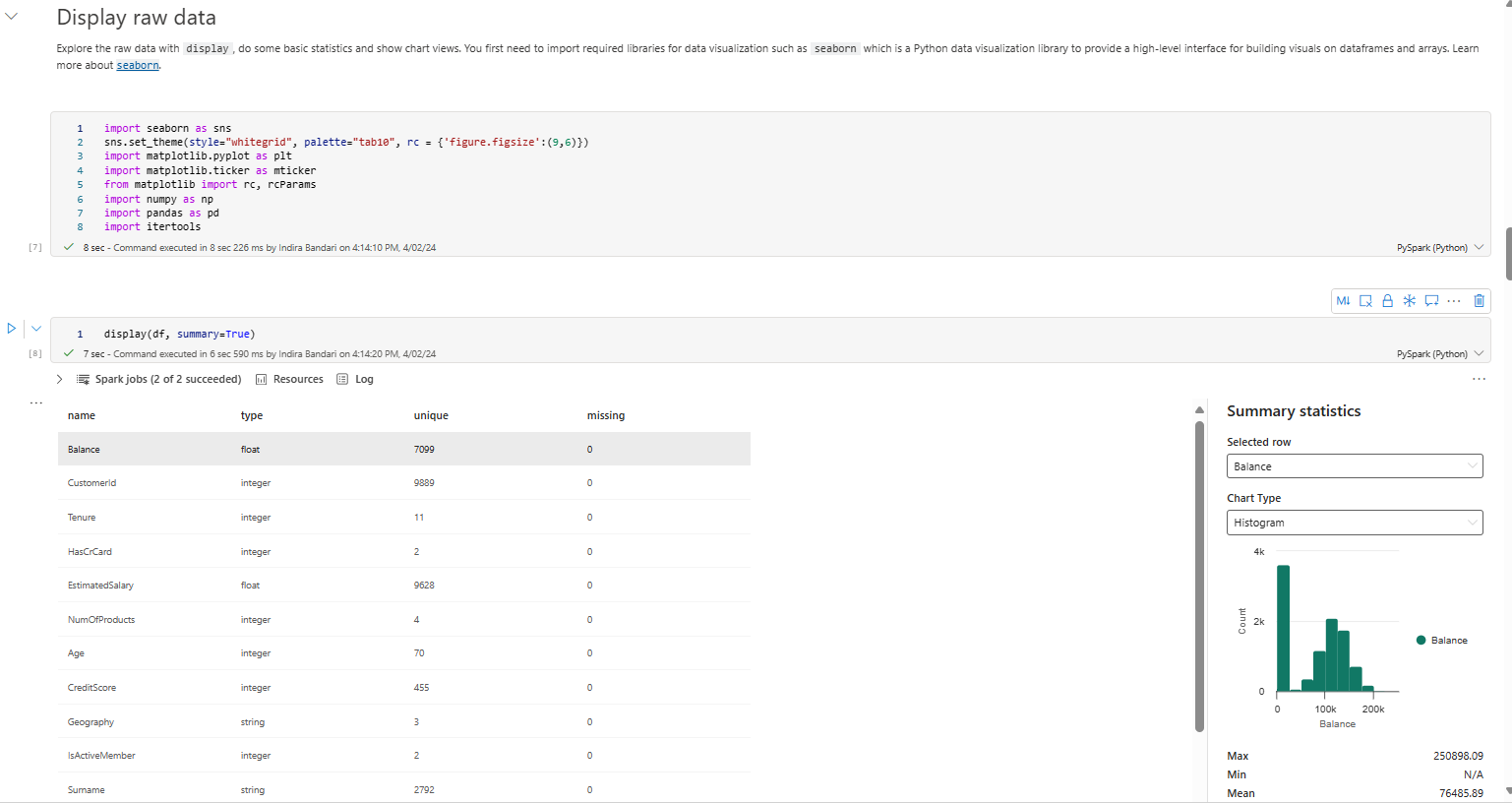
Also run the five number summary as shown below

Explore further by running the distribution of the exited and non exited customers as shown below

Run the distribution of numerical attributes

Perform feature engineering and one hot encoding

As a final step of Exploratory data analysis create a delta table by running the delta table code as shown below. You can also see the delta table named df_clean created in the lakehouse.

- Choosing Your Vessel: Azure Machine Learning serves as your shipbuilder. Here, you can choose and configure a machine learning algorithm suitable for churn prediction. Popular options include Logistic Regression, Random Forest, or Gradient Boosting Machines (GBMs).
Run the code in Step 4 of the notebook as shown below that will load the delta table and generate the experiment.
Now run the code that sets the experiment and auto logging, imports the scikit learn libraries and prepares the training and test data as shown below
- Training the Crew: Split your prepared data into training and testing sets. The training set feeds the algorithm, allowing it to "learn" the patterns associated with customer churn.
Now apply SMOTE to the training dataset and run the below query
Now train the model with Random Forest as shown below
Train the model with LightGBM too as shown below
- Fine-Tuning the Sails: Use hyperparameter tuning techniques to optimize the chosen algorithm's performance. This involves adjusting its parameters to achieve the best possible accuracy on the training data.
Track the model performance by observing the model metrics as shown below
- Testing the Waters: Evaluate your model's performance on the unseen testing data. Metrics like accuracy, precision, and recall will tell you how well the model predicts churn.
Load the best model and assess the performance against the test data as shown below
- Refinements & Improvements: Based on the evaluation results, you might need to refine your model by trying different algorithms, features, or hyperparameter settings. Iterate until you're satisfied with its performance.
Check the confusion matrix results as shown below
- Deploying the Model: Once the model performs well, save the prediction results to a delta file in the Lakehouse.
Save the results into the lakehouse by running the code as shown below
- Charting the Future: Leverage Power BI, seamlessly integrated with Fabric, to create compelling visualizations of your churn predictions. Segment customers based on their predicted churn probability, allowing for targeted interventions.
- Sharing the Treasure: Communicate your findings to stakeholders. Use Power BI dashboards to showcase the model's effectiveness and its potential impact on reducing customer churn.


